CTO室SREの侘美です。最近は社内のセキュリティ対策関連を生業にしております。
今回は最近進めていた社内のAWSアカウントのセキュリティ可視化がある程度形になったので記事にしたいと思います。
課題:多数のAWSアカウントのセキュリティをチェックしたい
サイバー攻撃が増加している昨今、AWSなどのPaaS環境においても構築時にセキュリティの観点で注意すべき点がいくつもあります。 例えば、不必要なサーバー/ポートがインターネットに公開されていないか、アカウントにMFAが設定されているか、等々実施しておきたいセキュリティ対策は多岐にわたります。
弊社では、AWSを用いてインフラを構築する際にセキュリティ上守るべきルール集を、インフラセキュリティポリシーというドキュメントを定義しています。 しかし、あくまでドキュメントベースなので、実際にこのドキュメントに書かれたルールに準拠した構成になっているかどうかのチェックは手作業で実施しなければならない状態でした。
また、サービスも年々増加しており、現在では約40のAWSアカウントを6名のSREで管理している状態であり、今後すべてのアカウントのセキュリティまわりをSREが手動でチェックしていくのは現実的ではありません。
さらに、現在はSREが中心に行っているインフラの構築/運用も各サービスチームへ徐々に移譲している途中であり、これらのセキュリティルールのチェックの自動化の必要性が上がってきました。
対策:セキュリティルール準拠状態の可視化
幸いAWSにはこういった課題を解決するためのサービスがいくつもあります。
- AWS Config
- AWS Security Hub
- Amazon Athena
- Amazon QuickSight
- Amazon Elasticsearch Service
- AWS Organizations
これらサービスを最大限活用し、社内のセキュリティポリシーで定義したルールへの準拠状態を可視化することを目標としました。
要件の整理
今回構築したアーキテクチャは以下の要件を元に作成しています。
- どのアカウントがどの程度セキュリティルールに準拠できているかがわかりやすく可視化できる
- できればフルマネージド
- Organizationにアカウントが増えてもメンテナンス不要で自動で対応される
- リソースの自動修復は現状考えていない
構成の検討
上記の要件を満たす構成を検討していく課程で、悩んだ・ハマったポイントをいくつかご紹介します。
AWS Config vs Security Hub
Organization配下のアカウント全体に対して、リソースがルールに準拠した設定になっているかをチェックするサービスとして、AWS ConfigやAWS Security Hubがあります。
AWS Configは「AWSが提供する151(2021/09/08現在)のマネージドルール」または「自身でLambda関数で実装したカスタムルーム」を使い、リソースのルールへの準拠状態をチェックすることができます。
また、AWS Organizationsにも対応しており、Organization配下の全アカウントに一括でルールを作成することができます。 ただし、アカウント横断でルール準拠状態を閲覧する方法は無いため、別途何らかの方法で可視化する必要があります。
Security Hubはセキュリティチェックの自動化とセキュリティアラートの一元化を主眼においたサービスです。 いくつか提供されているベストプラクティスを選択し、そのベストプラクティスに含まれるルールへの準拠がチェックされます。

こちらもOrganizationsに対応しており、配下のアカウントすべてを横断的にチェックすることができます。
Security Hubなら比較的少ない工数でOrganization配下のアカウントに対して横断的にチェックを実行できます。しかし、提供されたベストプラクティスのルール集でのチェックなので、今回実現したい社内のセキュリティポリシーに準拠しているかというチェックとは少しズレてしまいます。 また、ビューも固定なので「どのアカウントがセキュリティ的に弱いか」等を即座に判断するのは難しいです。
AWS Configはマネージドルールが豊富であり、社内でチェックしたい項目に合わせて柔軟に対応できそうです。 アカウント横断でのビューは無いため、何らかの方法で用意する必要があります。
弊社では既にSecurity Hubを全アカウントで有効化し、重要なセキュリティ項目に関しては適宜チェックし修正する運用を行ってはいましたが、今回はより柔軟なルールと求めているデータを可視化できるという点を優先し、AWS Configを採用することにしました。
QuickSight vs Elasticsearch Service
AWS Configを採用したので、アカウント横断の評価結果をいい感じに可視化する仕組みを別途用意する必要があります。
AWS Configは各リソースの評価状態をスナップショットログとして定期的にjson形式でS3に出力することができるので、このログを利用して可視化を行います。 スナップショットログは可視化のために一箇所に集めたいため、以下の図のような構成をとることで1つのS3バケットに全アカウント分集約しています。

上記のような方法でS3に格納されたログを可視化するソリューションはいくつも存在します。 AWS上で実現するメジャーな方法としては、「S3 → Athena → QuickSight」や「S3 → Lambda → Elasticsearch Service → Kibana」のような構成があげられます。 後者はSIEM on Amazon Elasticsearch Serviceというソリューションとして知られています。
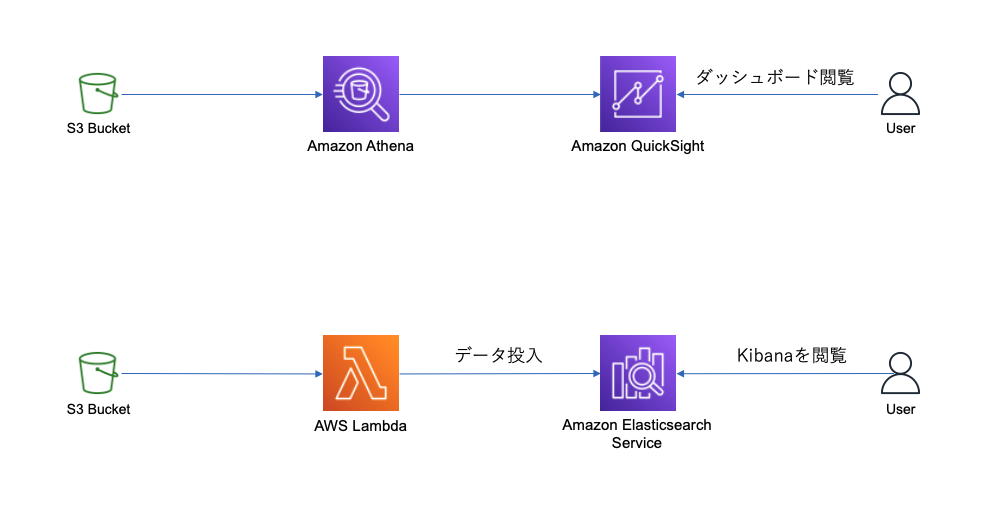
どちらの構成にもメリット・デメリットは存在しますが、今回は以下の理由からQuickSightを利用する構成を採用することにしました。
- IAMと連携したユーザー管理の容易性
- インスタンス管理の有無
- データ取り込み部分の実装コスト
- レポートメール機能
AWS Config マネージドルールの選定
2021/09/08時点で151のマネージドルールが提供されています。 docs.aws.amazon.com
ルール自体は「ルートユーザーのアクセスキーが存在しないこと」等様々な項目が用意されています。
この中からチェックしたい項目をピックアップし、
またセキュリティ以外の観点でもバックアップ、削除保護、可用性の観点などで設定が推奨していきたいルールもいくつかピックアップしました。
今回は合計で68ルールを採用しています。
これらをセキュリティ、コスト、パフォーマンス、バックアップ、削除保護の5つに分類し、それぞれの接頭詞(例:セキュリティなら security- )を決めた上で、ConfigのOrganization Config Ruleとして社内の全AWSアカウントへ登録しました。
接頭詞をルールを作成する際の名前に指定することで、スナップショット中のルール名から何の目的で導入したルールかを判別可能にし、ダッシュボードで可視化する際に「セキュリティルールに非準拠であるリソース数」のような表示も可能にしています。
最終的なアーキテクチャ
今回構築したアーキテクチャの全体像がこちらになります。
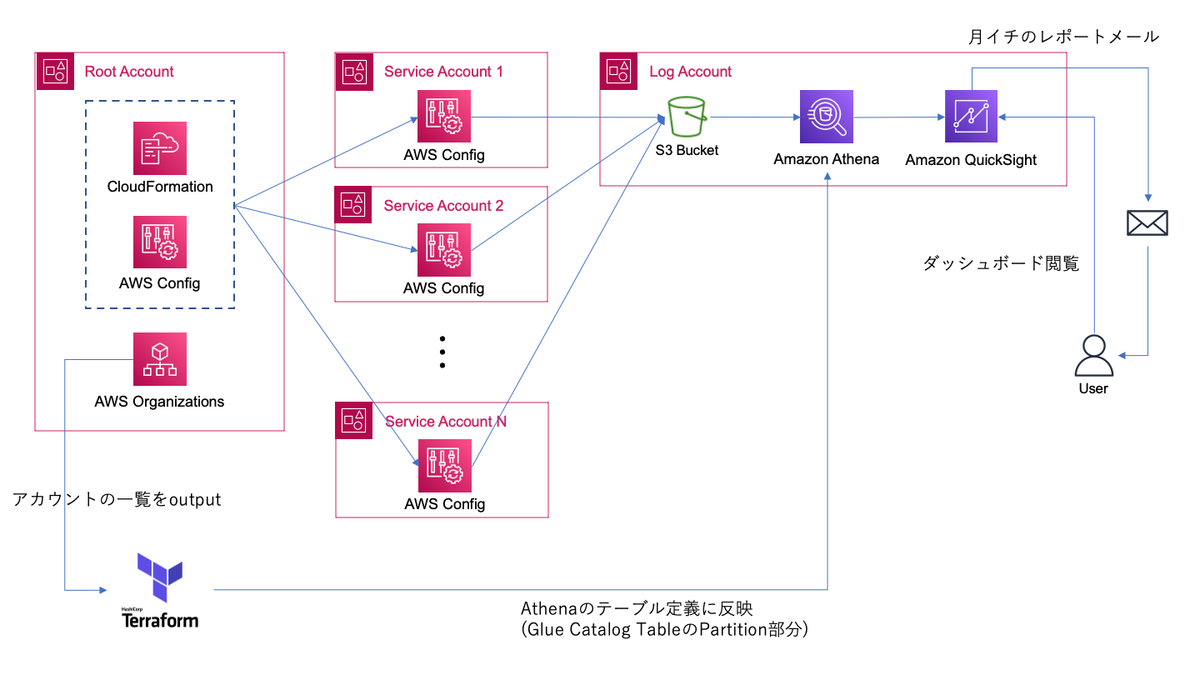
弊社ではAWS上のリソースはTerraformで管理しています。 また、Terraform CloudでStateの管理やapplyの実行を行っています。
Terraform Cloudのトリガー機能とWorkspace間のoutput参照機能を利用することで、Organizationを管理しているTerraformが出力する、アカウント一覧に変更があった場合、Log AccountのAthenaのテーブル定義を管理しているTerraformを実行するといった連携が可能になります。(詳細は後述します)
この手のダッシュボードでは、能動的な閲覧のみで運用を続けていると、閲覧するメンバーが固定化され仕組みが風化していく懸念があります(体験談)。 そこで、QuickSightの機能で定期的にダッシュボードをレポートとして送信することで、関与するメンバーが定期的に閲覧してくれるように試みています。
ハマりポイント:AthenaのProjection Partition
S3に保存したConfigのスナップショットに対してAthenaでクエリを実行するためにテーブルを作成する必要があります。 その際のテーブル定義で一部ハマった箇所があったのでご紹介します。
前提:Partition Projectionの型
Athenaのテーブル設定の一つの項目に、パーティションという概念があります。 パーティションを簡単に説明すると、S3のキー中のどの位置にどのような変数が含まれるかを設定し、SQL中でその値を指定することでスキャン対象となるS3上のオブジェクトを限定することができます。
例えば、S3バケットのキーに /AWSLogs/111111111111/Config/ap-northeast-1/2021/9/1/ConfigSnapshot/ のように日付が含まれる場合、日付部分をパーティションとして登録することで、 WHERE date = '2021/9/1' のようなクエリを実行できるようになります。
大量のオブジェクトがあるS3に対してパーティションを適切に設定せずにAthenaでクエリを実行するとコストがかかったりエラーが発生したりするのでAthenaを使う上では必須のテクニックとして知られています。
パーティションの設定方法にはいくつか種類があります。
- Hive形式のキーを利用する
ADD PARTITIONクエリを実行する- Projection Partitionを利用する
各方法の細かい違いに関しては公式ドキュメントを参照していただくのが良いかと思います。
今回はConfigのスナップショットが対象になるため、1のHive形式のキーではないのでこの方法は使えません。 2と3で迷い、AWSのSAやプロフェッショナルの方とディスカッションさせていただき、 Projection Partitionを利用する方が良さそうという結論 に至りました。
議論のポイントとなったのは、S3オブジェクトのキーに含まれるアカウントID部分をProjection Partitionのどの型で表現するかという点です。
Projection Partitionでサポートされる型には、 Enum, Integer, Date, Injected の4種があります。
参考:Supported Types for Partition Projection - Amazon Athena
アカウントIDは12桁の数字なので、 Enum, Integer, Injected が候補となります。
それぞれの特徴は以下のようになっています。
Enum: テーブル定義時に取りうる値を列挙する。検索時の指定は任意。Integer: テーブル定義時に取りうる値の範囲を指定する。範囲が広すぎる場合検索クエリがタイムアウトする。検索時の指定は任意。Injected: テーブル定義時に値の指定は不要でキーに含まれる値を自動的に判定してくれる。検索時の指定は必須。
AWSアカウントは任意のタイミングで増減するため、できれば現存するアカウントを列挙し指定するようなパーティションの設定は避けたいです。これはAWSアカウントをOrganizationに追加した際に特にメンテナンスすることなく可視化用のダッシュボードに反映されて欲しいからです。
そうなると、 Injected 型が候補になってきますが、検索時に値の指定が必須となってしまうため、アカウント横断で検索するようなクエリを実行できなくなってしまうため却下となります。
Integer 型なら12桁の整数も対象なので、これで条件を満たせると思い、実際にPartition Projectionを設定してAthenaから検索クエリを実行してみました。
ところが、検索クエリがタイムアウトしてしまいました。
Integer 型の取りうる範囲の指定を調整して何度か実験したところ、12桁のAWSアカウントの範囲を値域として指定すると範囲が広すぎるためかタイムアウトとなることがわかりました。
課題:アカウントの増減への対応
ということで、 Enum 型でテーブル定義時に現存するOrganization配下のアカウントを列挙する必要がでてきました。
この Enum 型でのPartition Projectionを設定した状態での検索クエリの挙動は特に問題なく、想定している結果を得ることができました。
つまり、このEnum 型の場合、Organization配下にAWSアカウントが増えた場合に如何に自動でPartition Projectionの定義にアカウントIDを反映するかという課題が残ります。
(Partition Projectionの変更はテーブル作成後でも実行できます)
対策:TerraformのRemote Stateの活用
この課題を解決するにあたり、弊社で利用しているTerraform Cloudの機能を利用するのが最もスマートであることに気づきました。
Terraform CloudはHashiCorp社が提供している、Terraformの実行環境です。指定したブランチに反映されたTerraformのコードを使い自動でapplyを実行してくれます。 弊社ではAWSのリソースはTerraformで管理しており、SREが管理する全てのTerraformのリポジトリをTerraform Cloud上でapplyしています。 また、Organization配下にアカウントを新規に開設する場合も、Terraformで実装しています。 今回のConfigやAthenaに関しても同様です。
Terraform Cloudを利用すると、あるworkspaceの出力( output )を別のworkspaceから参照するRemote State機能を利用することができます。
参考: Terraform State - Workspaces - Terraform Cloud and Terraform Enterprise - Terraform by HashiCorp
また、特定のworkspaceのapplyが完了したのをトリガーに、別のworkspaceのapplyをキックすることが可能です。
参考: Run Triggers - Workspaces - Terraform Cloud and Terraform Enterprise - Terraform by HashiCorp
つまり、以下のような構成にすることで、Organizationにアカウントが追加された場合に自動でAthenaのProjection Partitionの設定を変更することが可能になります。
- Organizationを管理するTerraform Workspaceにて、アカウントの一覧を
outputで出力する - AthenaのPartition Projectionを構築するTerraform Workspaceにて、上記のアカウント一覧を参照して
Enum型の値に設定する - Organizationを管理するTerraform Workspaceが実行されたら、Athenaを管理するTerraform Workspaceのapplyが実行されるように、Run Triggerを設定する
全体のアーキテクチャから抜粋すると、以下の部分がこの仕組を表しています。

テーブル定義は最終的に以下のTerraformコードにより作成しました。
resource "aws_glue_catalog_table" "config" {
name = "aws_config"
owner = "hadoop"
database_name = aws_glue_catalog_database.config.name
table_type = "EXTERNAL_TABLE"
parameters = {
EXTERNAL = "TRUE"
"projection.enabled" = "true"
"projection.account.type" = "enum"
"projection.account.values" = join(",", values(data.terraform_remote_state.root.outputs.accounts)) # Remote Stateで別WorkspaceからアカウントIDの配列を参照
"projection.region.type" = "enum"
"projection.region.values" = "ap-northeast-1,us-east-1"
"projection.dt.type" = "date"
"projection.dt.range" = "2021/4/1,NOW"
"projection.dt.format" = "yyyy/M/d"
"projection.dt.interval" = "1"
"projection.dt.interval.unit" = "DAYS"
"projection.itemtype.type" = "enum"
"projection.itemtype.values" = "ConfigHistory,ConfigSnapshot"
"storage.location.template" = "s3://<your bucket name>/<prefix>/AWSLogs/$${account}/Config/$${region}/$${dt}/$${itemtype}"
}
partition_keys {
name = "account"
type = "string"
}
partition_keys {
name = "region"
type = "string"
}
partition_keys {
name = "dt"
type = "string"
}
partition_keys {
name = "itemtype"
type = "string"
}
storage_descriptor {
location = "s3://<your bucket name>/<prefix>/AWSLogs"
input_format = "org.apache.hadoop.mapred.TextInputFormat"
output_format = "org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat"
ser_de_info {
serialization_library = "org.openx.data.jsonserde.JsonSerDe"
parameters = {
"serialization.format" = "1"
"case.insensitive" = "false"
"mapping.arn" = "ARN"
"mapping.availabilityzone" = "availabilityZone"
"mapping.awsaccountid" = "awsAccountId"
"mapping.awsregion" = "awsRegion"
"mapping.configsnapshotid" = "configSnapshotId"
"mapping.configurationitemcapturetime" = "configurationItemCaptureTime"
"mapping.configurationitems" = "configurationItems"
"mapping.configurationitemstatus" = "configurationItemStatus"
"mapping.configurationitemversion" = "configurationItemVersion"
"mapping.configurationstateid" = "configurationStateId"
"mapping.configurationstatemd5hash" = "configurationStateMd5Hash"
"mapping.fileversion" = "fileVersion"
"mapping.resourceid" = "resourceId"
"mapping.resourcename" = "resourceName"
"mapping.resourcetype" = "resourceType"
"mapping.supplementaryconfiguration" = "supplementaryConfiguration"
}
}
skewed_info {
skewed_column_names = []
skewed_column_value_location_maps = {}
skewed_column_values = []
}
number_of_buckets = -1
columns {
name = "fileversion"
type = "string"
}
columns {
name = "configsnapshotid"
type = "string"
}
columns {
name = "configurationitems"
parameters = {}
type = "array<struct<configurationItemVersion:string,configurationItemCaptureTime:string,configurationStateId:bigint,awsAccountId:string,configurationItemStatus:string,resourceType:string,resourceId:string,resourceName:string,ARN:string,awsRegion:string,availabilityZone:string,configurationStateMd5Hash:string,configuration:string,supplementaryConfiguration:map<string,string>,tags:map<string,string>,resourceCreationTime:string>>"
}
}
}
可視化した内容
最後にQuickSightで構築したダッシュボードの一部を紹介します。(一部加工しております)

主に、「次にテコ入れすべきAWSアカウントの特定」や「全体的に実践できていないルール = 社内にノウハウがないルール」の特定などに利用する想定で作成しております。
課題
今回構築した構成の中で課題として残っている部分もあるので掲載しておきます。
- QuickSightのリソースのほとんどがTerraformに対応してない
- SQLのみリポジトリ管理している状態で、aws providerの対応待ち
- 特定のリソースを除外する対応が難しい
- タグでの除外とかができれば嬉しいが現状はできない
まとめ
Organization配下のAWSアカウントのルールへの準拠状態を、AWS Config + Athena + QuickSightで可視化することができました。 これで今後AWSアカウントが増加したり、各アカウントの管理をサービス開発チームへ移譲していってもある程度のガバナンスが効いた状態を担保することができるようになったかと思います。
メドピアでは一緒に働く仲間を募集しています。 ご応募をお待ちしております!
■募集ポジションはこちら
https://medpeer.co.jp/recruit/entry/
■開発環境はこちら