CTO室SREの @kenzo0107 です。
2021年6月24日に「 kakari for Clinic ホームページ制作 」がリリースされました。

今回は上記サービスで採用した、
AWS + ngx_mruby で構築した SSL 証明書の動的読み込みシステムについてです。
SSL 証明書を動的に読み込みする理由
kakari for Clinic ホームページ制作の1機能で、制作したホームページに独自ドメインを設定する機能がある為です。*1

複数ドメインでアクセスできる
=複数ドメインの SSL 証明書を読み込む
を実現する必要があります。
動的に SSL 証明書を読み込むには?
以下いずれかのモジュールを組み込むことで SSL 証明書の動的読み込みが可能になります。
以下理由から ngx_mruby を採用しました。
- 弊社は Ruby エンジニアの割合が高い!
- 技術顧問 Matz さんに相談できる!*2
ngx_mruby での SSL 証明書動的読み込み 実装 参考資料
論文「高集積マルチテナントWebサーバの大規模証明書管理」を参考にさせていただきました。
p4 の「図3 動的なサーバ証明書読み込みの設定例 (KVS ベース)」を見ると実装概要がわかりやすいです。
server {
listen 443 ssl;
server_name _;
ssl_certificate /path/to/dummy.crt;
ssl_certificate_key /path/to/dummy.key;
mruby_ssl_handshake_handler_code ’
ssl = Nginx::SSL.new
host = ssl.servername
redis = Redis.new "127.0.0.1", 6379
crt, key = redis.hmget host, "crt", "key"
ssl.certificate_data = redis["#{host}.crt"]
ssl.certificate_key_data = redis["#{host}.key"]
’;
}
通常、 Nginx の ssl_certificate, ssl_certificate_key に変数を利用できません。 ngx_mruby を利用すると Redis or その他から証明書情報 crt, key を取得し、 設定することができます。
システム構成
右側のシステム管理者・運営者が管理画面から静的コンテンツを S3 に生成しています。
今回は ngx_mruby での証明書の動的配信についてフォーカスして紹介します。*3
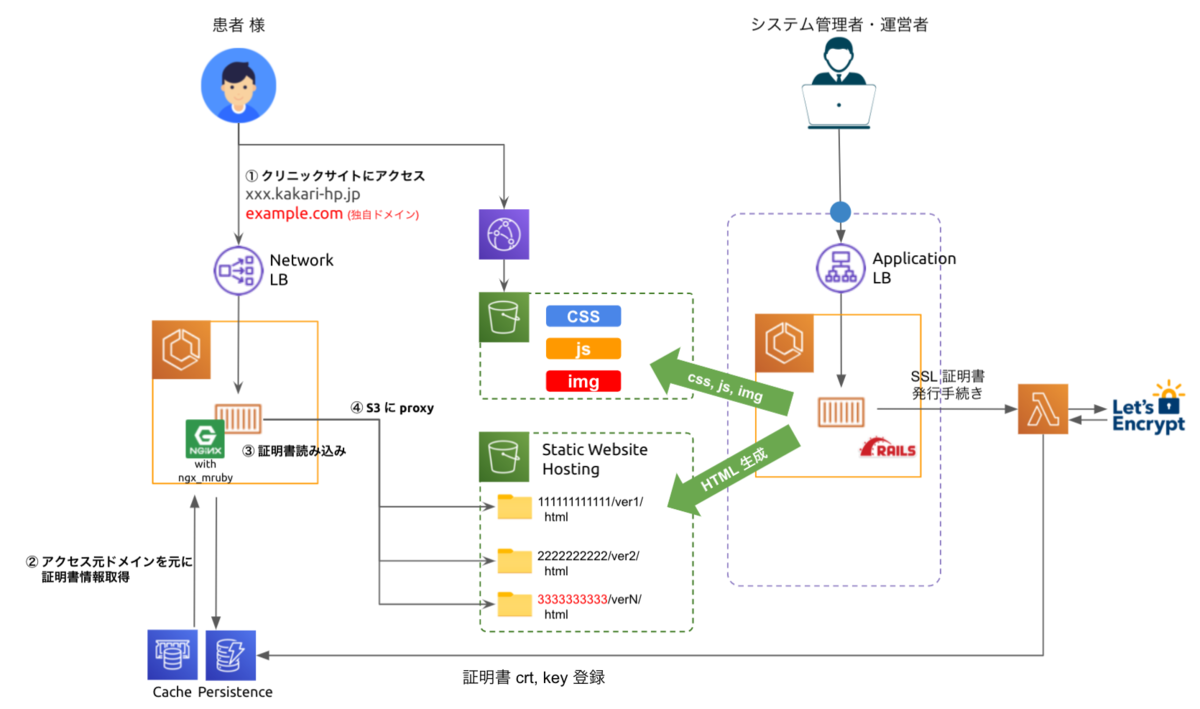
ユーザアクセスからのサイトのコンテンツ配信する大まかな流れは以下の通りです。
- 患者様 がクリニックサイトにアクセス
- ngx_mruby で SSL/TLS ハンドシェイク時にドメインを元に Redis から証明書(crt), 秘密鍵(key) を取得
- Redis に存在しない場合は DynamoDB から取得し、 Redis にキャッシュ登録
- 取得した crt, key を元に SSL/TLS ハンドシェイク
- 静的ウェブサイトとしてホスティングされた S3 へ proxy し HTML を表示
- HTML 内の各種 css, js, img は CDN で配信
システムの詳細・工夫点を以下に記載して参ります。
Nginx を Fargate で起動させる
ngx_mruby を組み込んだ Nginx は Fargate 上で起動させました。
サーバ管理・デプロイやスケーリングの容易さのメリットが大きい為、Fargate を採用しました。
Fargate では net.core.somaxconn が変更できません が、 リクエスト詰まりしない様、タスク数には余裕を持たせています。
Docker イメージは https://github.com/matsumotory/ngx_mruby/blob/master/Dockerfile を参考に alpine でマルチステージビルドし軽量化 (850 MB → 26 MB) しました。
イメージビルドや ECS へのデプロイは GitHub Actions で実施しています。
SSL 終端を Nginx で実施すべく NLB を採用
ALB, CLB では HTTPS (443) 通信する場合は、証明書の設定が必須です。
NLB は TCP (443) を指定し SSL 終端を Target で実施でき、Fargate との親和性も高い為、採用しました。

ALB は ロードバランサーあたりの証明書 (デフォルト証明書は含まない): 25 であること等、クォータ制限 がある為、AWS LB シリーズでの SSL 終端はサービスがスケールすることを考慮すると採用できませんでした。
証明書発行は ACM でなく Let's Encrypt を採用
ACM 証明書数 クォータ 制限がある為、サービスがスケールすることを考慮して証明書の発行は Let's Encrypt で実施することとしました。*4
過去に業務で利用経験があり、また本件で参考にさせていただいたはてなブログさんでも採用していること、また、プロジェクトが開始される頃に Software Design 2021年4月号 で特集されており、発行の手軽さと信頼性から採用しました。
NLB 利用時の注意点
NLB は ALB と異なり、以下を注意する必要がありました。*5
- セキュリティグループがアタッチできない
- WAFがアタッチできない
- 4xx, 5xx 等のメトリクスがない
対策: セキュリティグループがアタッチできない
セキュリティグループで実施していた IP 制限は ngx_mruby で実装しました。
- allow_request.rb
# frozen_string_literal: true # リクエスト許可処理クラス class AllowRequest def initialize(request, connection) @r = request @c = connection end def allowed_ip_addresses ENV['ALLOW_IPS'].split(',') end def allowed? return true unless (allowed_ip_addresses & [ @c.remote_ip, @r.headers_in['X-Real-IP'], @r.headers_in['X-Forwarded-For'] ].compact).empty? false end AllowRequest.new(Nginx::Request.new, Nginx::Connection.new).allowed? end
nginx.conf
env ALLOW_IPS; ... # 許可 IP でない場合、 404 を返す mruby_set $allow_request /etc/nginx/hook/allow_request.rb cache; if ($allow_request = 'false') { return 404; }
環境変数 ALLOW_IPS に許可したい IP を渡すと ngx_mruby で許可 IP 以外は 404 を返します。
NLB + Nginx on Fargate でクライアント IP を渡す方法
NLB は Target Group のプロトコルが TCP or TLS の場合、 クライアント IP 保持はデフォルトで無効化されています。*6
その為、明示的にクライアント IP の保持を有効化する必要があります。

Proxy protocol v2 も有効化し、Nginx で proxy_protocol を設定することで、Nginx でクライアント IP を解釈できる様になります。
server {
listen 443 ssl proxy_protocol;
server_name _;
対策: WAF がアタッチできない
NLB には WAF がアタッチできません。
XSS, SQLi 等の WAF は Nginx に NAXSI *7 を導入することで対応しました。*8
location / {
# NAXSI による SQLi, XSS 等検知しブロックした場合、403 を返す
SecRulesEnabled;
DeniedUrl /request_denied;
CheckRule "$SQL >= 8" BLOCK;
CheckRule "$XSS >= 8" BLOCK;
CheckRule "$RFI >= 8" BLOCK;
CheckRule "$TRAVERSAL >= 4" BLOCK;
CheckRule "$EVADE >= 4" BLOCK;
# whitelist: XSS double encoding が誤検知された為、許容する
BasicRule wl:1315;
...
}
# WAF でブロックした際に 403 を返す
location = /request_denied {
return 403;
}
誤検知した際には特定ルールをホワイトリストとして登録し許容することが可能です。*9
ブロック時には Nginx エラーログに出力されます。*10
2021/06/11 17:53:32 [error] 7#0: *53 NAXSI_FMT: ip=172.21.0.1&server=example.com&uri=/%25U&vers=1.3&total_processed=13&total_blocked=11&config=block&cscore0=$EVADE&score0=4&zone0=URL&id0=1401&var_name0=
対策: 4xx, 5xx メトリクスがない
NLB は ALB とは異なり 4xx, 5xx メトリクスがなく、エラー検知ができません。
以下の様に対応しました。

- fluentbit で Nginx のログを CloudWatch Logs へ配信
- CloudWatch Metric Filter で 4xx, 5xx エラーをフィルタリング*11
- CloudWatch Alarm で 4xx, 5xx の数が閾値を超えると SNS 経由で Chatbot へ通知*12
- Chatbot と連携した Slack へ通知
CloudWatch Logs は通知用に利用し
Kinesis Firehose + S3 は Athena でログ捜査時に利用します。
RDS でなく DynamoDB でデータ永続化
ngx_mruby のサンプルコードでは、証明書情報を Redis でキャッシュし、 RDS で永続化するパターンがよく見られました。
ですが、今回は DynamoDB を採用しています。
理由は、ドメイン名をキーに証明書情報を取得する今回のケースでは複雑なクエリを実行する必要がなく、リレーショナル DB と比較して NoSQL の特徴である以下メリットを享受できる為です。
- 柔軟でスキーマレスなデータモデル
- 水平スケーラビリティ
- 分散アーキテクチャ
- 高速な処理
参考: 何が違う?DynamoDBとRDS - サーバーワークスエンジニアブログ
DynamoDB へのアクセスは API Gateway + Lambda
ngx_mruby は https://rubygems.org/ の gem を利用できません。 *13
低レベル API を mattn/mruby-curl で実現できないこともなさそうですが、難易度が高く検証工数を確保できそうにない点から見送りました。
その代わりに
Lambda で aws-sdk を利用し DynamoDB へアクセスする様にしました。
API Gateway で Lambda のエンドポイントを設定し ngx_mruby から mattn/mruby-curl でエンドポイントを叩き Lambda を実行する様にしました。

上記構成で数十ミリ秒程度でレスポンスが返り商用環境の利用は問題ありませんでした。
ちなみに、 永続化データを担保する DynamoDB へのアクセスは以下の場合となり、基本的に頻度は低いです。
- ElastiCache Redis にアクセスできない
- ElastiCache Redis のデータが揮発した*14
証明書の自動更新 システム構成

概要は以下の通りです。
- EventBridge (cron) で Lambda
cert-lifecycle-storeを定期実行 cert-lifecycle-storeで証明書の有効日数が 30日以下の証明書のドメインリストを取得*15cert-lifecycle-storeからcert-updaterにドメイン名を渡し証明書の更新を実行cert-updaterで go-acme/lego を利用し Let's Encrypt で証明書を発行- SSL 証明書 (crt) と 秘密鍵 (key) を DynamoDB, ElastiCache Redis に保存、バージョン管理として S3 に証明書発行時のレスポンスを JSON ファイルに保存
証明書の新規発行は管理画面から cert-updater を実施できる様にしており、運用者が証明書を発行できる様にしています。
参考
おまけ
mruby 仲間を増やしたい気持ちから今回の ngx_mruby を用いた証明書の動的読み込みを簡易的に体験できるリポジトリを用意しました。
ngx_mruby 初めましての方もそうでない方も遊んでいただけると幸いです。
以上です。
採用のリンク
メドピアでは一緒に働く仲間を募集しています。 ご応募をお待ちしております!
■募集ポジションはこちら
https://medpeer.co.jp/recruit/entry/
■開発環境はこちら
https://medpeer.co.jp/recruit/workplace/development.html
*1:弊社テックブログでも利用しております、はてなブログの「独自ドメイン」の設定と同様の機能です。
*2:弊社では定期的に Matz さんへ聞きたいこと!会を開催頂いております。
*3:Ruby on Rails で構成される管理画面で静的コンテンツをS3にアップロードする仕組みについては別途本ブログで紹介予定です。お楽しみに✨
*4:プロジェクト開始前に弊社担当の AWS ソリューションアーキテトに相談したところ、サービスがスケールすることを考慮すると ACM でなく別途証明書発行システムを採用することを推奨されました。
*5:弊社では NLB は本プロジェクトが初採用でした。
*6: NLB Client IP preservation にて「If the target group protocol is TCP or TLS, client IP preservation is disabled by default. 」と記載がある通りです。
*7:NAXSI は Nginx Anti XSS & SQL Injection の略で Nginx 特化の WAF モジュールです。
*8:Nemesida WAF Freeは alpineベースだと導入方法がわからなかった(できなかった)。Nginx Plus ModSecurityは年間40万円以上の有償サービスで検証工数が確保できず、断念しました。
*9:w:1315 の 1315 は ルールに採番されているIDで https://github.com/nbs-system/naxsi/blob/master/naxsi_config/naxsi_core.rules に記載されています。
*10:LOG を設定するとブロックせずログに出力するモードがある様ですが、LearningMode (学習モード)を設定しないと「Assertion failed: strlen(fmt_config) != 0 (/usr/local/src/naxsi/naxsi_src//naxsi_runtime.c: ngx_http_nx_log: 1076)」というエラーが発生することを確認しています。AWS WAF の count の様な機能を期待していましたが違いました。
*11:CloudWatch Metric Filter のアイコンが見つからなかった
*12:SNS 連携先を Lambda でなく Chatbot にした場合、通知内容を
*13:その代わり https://github.com/mruby/mgem-list にある gem を利用できます
*14:よくある質問 - Amazon ElastiCache | AWS にて「エンジンのアップグレードプロセスは、既存のデータをベストエフォートで保持するように設計されており、Redis レプリケーションに成功する必要があります。」とあり、データは揮発する可能性があることを前提に設計しています。
*15:Let's Encrypt の証明書の有効期間は 90 日間で 60日毎の更新を推奨している為です