Noita世界の理不尽をこの身をもって体験した末にバウンドルミナスで全てを切り刻んでクリアしました、フロントエンドグループの小宮山です。
以前からこれできたらいいのになぁと思いながら無理そうと諦めていた掲題の事柄を実現できた嬉しさの勢いのままに書き始めています。
状況
1枚岩なMPAプロダクトがどういうものかというと、
- ルーティングをRails側で管理するMPA(複数エントリーポイント)
- 異なる種別のユーザー向けシステムが複数内包されている
という構成です。
ルーティングについては要するにSPAではなく、ページ毎のhtmlファイルとmain.jsがあるということです。
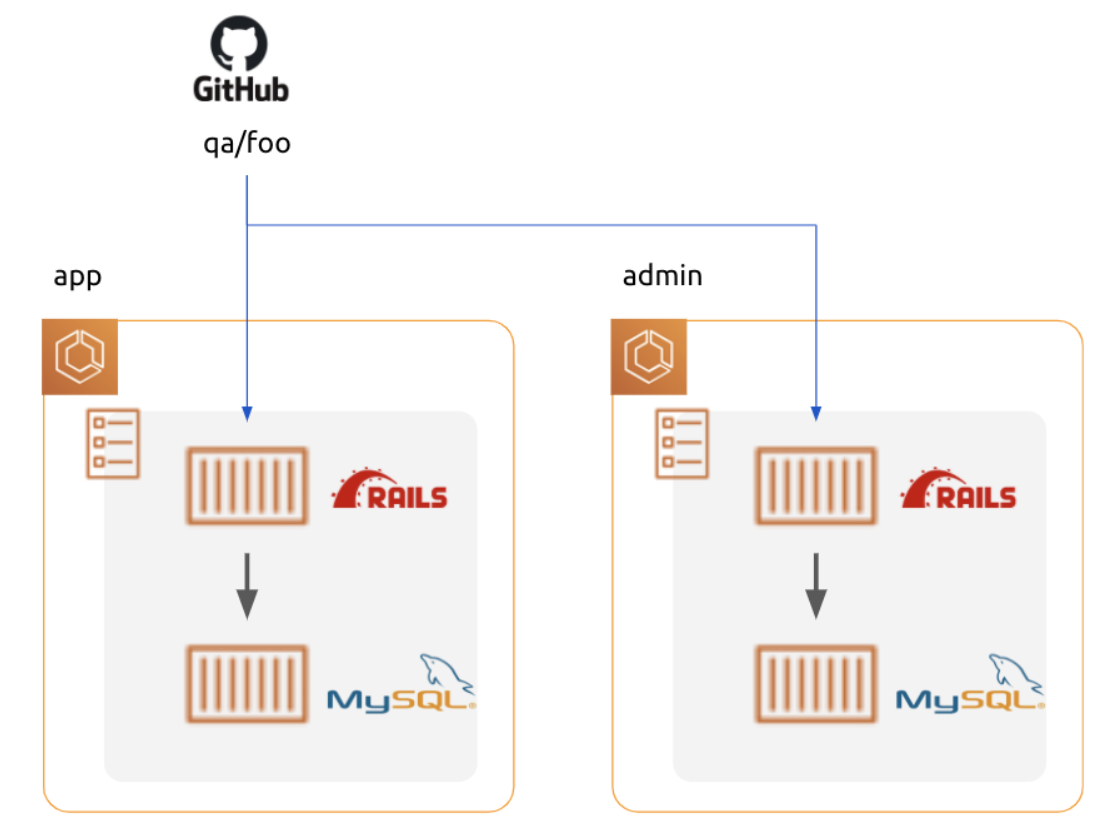
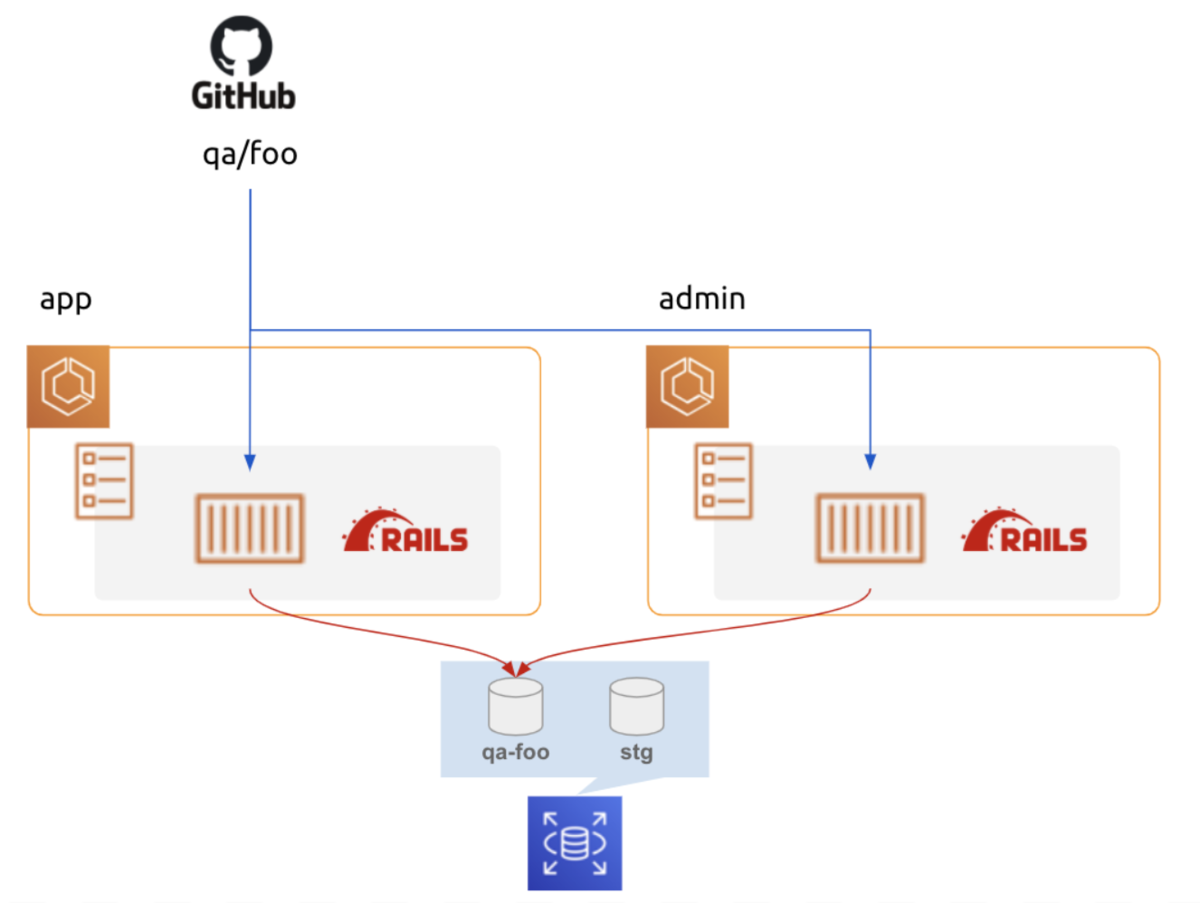
異なる種別というのは、要するにユーザー向け画面と管理者向け画面が分かれているような状況です。場合によっては3種類、4種類以上の異なるシステムが内包されたりもします。BtoBtoCなサービスだったりする場合ですね。
課題感
このような状況で普通にWebpack設定を組み上げると、もちろん全てのフロントエンドアセットをひっくるめて同じ設定でビルドすることになります。幸いWebpackはマルチエントリーなビルドにも対応しているのでビルド自体に難しさはありません。
一方で、異なる種別のユーザー向けのフロントエンドアセットを一緒くたにビルドするとやや困ったことが起きてきます。
特に気になっていたのが、splitChunksによる複数画面利用モジュールの切り出しに関することです。
SPAと異なりMPAの場合は画面遷移毎にscriptファイルのロードが行われるため、例えばVue.jsなど、ほぼ全画面で利用するようなモジュールは個別のエントリーファイルに入れてしまうとパフォーマンスの低下が懸念されます。
そこでsplitChunksをいい感じに設定していい感じに切り出すわけですが(いい感じの切り出し方は無限に議論があるので今回は触れません)、困ったことにこの切り出しが全ユーザー種別を跨って行われてしまいます。
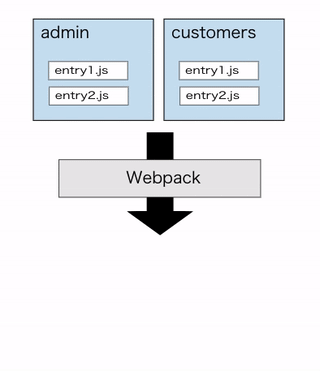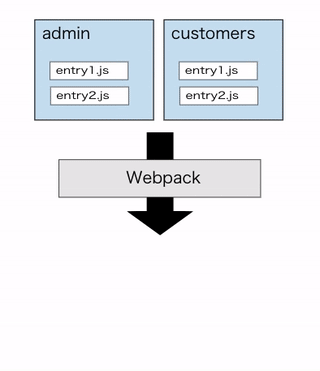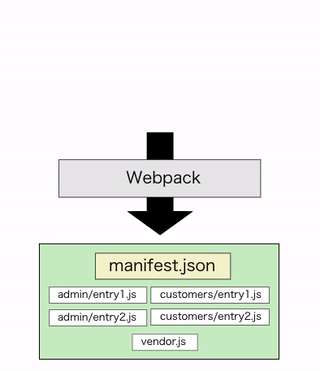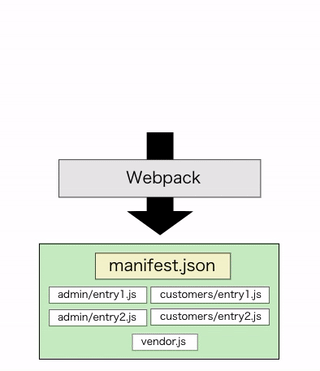
シンプルな例を挙げると、管理画面でしか使わない重厚なリッチエディタ用モジュールが、splitChunksの対象となることでそれを全く必要としないユーザー向け画面でも取得対象に含まれてしまったような状況です。
node_modules配下を丸ごとvendor.jsに切り出すような設定をしているとあるある状況だと思われます。
妥協案
Webpackビルドをユーザー種別ごと別々に行えば当然ですが上記のような問題は起きません。しかしこれはこれで様々な面倒事が付きまといます。
ルーティングをバックエンドで制御している場合、フロントエンドアセットはmanifest.jsonで管理することが多いと思われます。
Webpackビルドを分けた場合、当然このmanifest.jsonも複数種類出力されることになります。つまりバックエンドも複数のmanifest.jsonを読み分けるような処理をしないといけません。既にやりたくありません。
複数のWebpackビルドを実行しなければいけない点も見逃せません。複数のWebpackビルドを--watchモードで動かしながら開発することに喜びを見出す会の皆様には申し訳ないですが、複数のWebpackビルドを--watchモードで動かしながら開発することに喜びを見出すことは私のような一般フロントエンドエンジニアには不可能でした。
このような様々な不便が付きまとうことから、多少のパフォーマンス悪化には目をつぶってまるごと単一のWebpackビルドで片付けてしまっていたのが現状でした。
光明
1シーズンに1回くらいの頻度でこの課題感と無理感の再発見を繰り返してきていて、今シーズンも再発見に勤しもうと思ったら実はなんとかなりそうなピースが揃っていることに気がつきました。
ピースその1
実はWebpackは複数の設定を配列で持つことができます。
リンク先にもある通り、こういう書き方ができます。
module.exports = [
{
output: {
filename: './dist-amd.js',
libraryTarget: 'amd',
},
name: 'amd',
entry: './app.js',
mode: 'production',
},
{
output: {
filename: './dist-commonjs.js',
libraryTarget: 'commonjs',
},
name: 'commonjs',
entry: './app.js',
mode: 'production',
},
];
このビルドを実行すると、2つの設定に基づいたビルドを同時(内部的には順次かもしれません)に走らせてくれます。
サンプルコードのように用途別に生成物を分けたり、ユニバーサルJSなプロダクトでサーバーとクライアント環境それぞれをビルドしたいような場面で活躍しそうです。
ユーザー種別ごとに異なる設定を用意したいという場面も状況は同じなので、きっとそのまま適用できるでしょう。
「複数のWebpackビルドを実行しなければいけない」という問題はこれでなんとかなりそうです。
If you pass a name to --config-name flag, webpack will only build that specific configuration.
なんと名前を付けておくと特定の設定でだけビルドすることもできるようです。admin系画面が不要な開発中はビルド対象から外して高速化するといった使い方もできそうです。
ピースその2
Webpackプラグインとしてmanifest.jsonをいい感じに生成してくれるのがwebpack-assets-manifestで、このプラグインにはmergeというオプションがあります。
このmergeオプションを有効にするとその名の通り、同名のmanifest.jsonファイルが既に存在している場合、そこに追記する形で新たなmanifest.jsonを生成してくれるようになります。
前回生成したmanifest.jsonを一部引き継ぐなんて絶対面倒な何かを引き起こす厄介な機能じゃないと勘ぐりたくなりますが、実はこのオプションが欲しい状況が存在します。
今回なんとかしたかった状況が正しくそれでした。ユーザー種別ごとに異なる設定でWebpackビルドを行いつつ、最終的なmanifest.jsonは1つに統合することが可能となります。
マルチエントリーグルーピングビルド設定
以上のピースを当てはめるとこのようなWebpack設定を組み上げることが可能です。
app/javascript/packs配下にエントリーファイルが設置されるとして、さらに顧客用画面はcustomers、管理用画面はadminでネームスペースを切っているような例です。
- app
- javascript
- packs
- entry.js
- customers
- entry.js
- admin
- entry.js
そして生成されるmanifest.jsonはこのようになります。個別のエントリーファイルは以前同様に生成されつつ、splitChunksしたvendor系ファイルはネームスペース毎の個別で生成してくれています。
{ /* 略 */ "entry": "/packs/entry.abc-hash.js", "customers/entry": "/packs/customers/entry1.abc-hash.js", "admin/entry": "/packs/admin/entry1.abc-hash.js", "vendor-root.js": "/packs/vendor-root.abc-hash.js", "vendor-customer.js": "/packs/vendor-customers.abc-hash.js", "vendor-admin.js": "/packs/vendor-admin.abc-hash.js", }
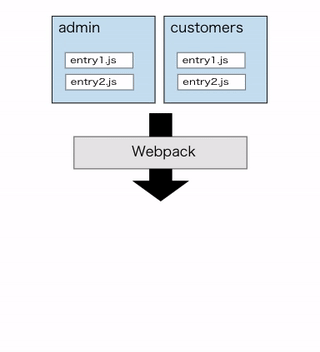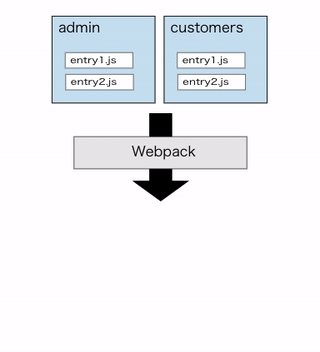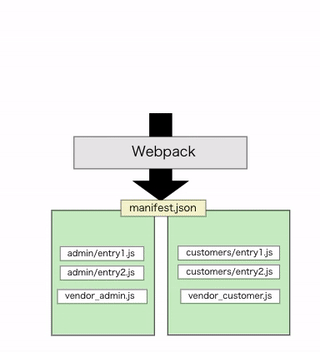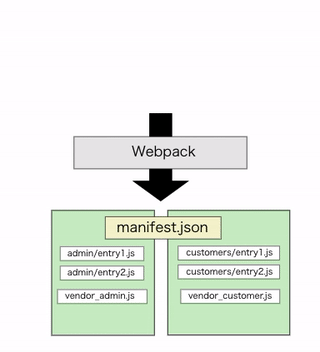
注意点として、splitChunksしたファイルを実際に読み込むhtmlファイルはネームスペース毎に別で用意する必要があります。
とはいえ全ユーザー種別で単一のlayoutファイルを使い回すことは稀で、それぞれ専用のlayoutファイルを用意するケースがほとんどだと思われます。manifest.jsonをhelperで読み分けるような面倒さに比べたらきっと些細なことです。
おわり
異なるユーザー種別向けの設定を別で用意しつつ、ビルド自体は統合されているようにふるまわせたいという贅沢な願いはこうして無事に叶えることができました。 Webpackを素で触れる環境はやはりよいものです。皆様も素敵なWebpackライフを。
メドピアでは一緒に働く仲間を募集しています。 ご応募をお待ちしております!
■募集ポジションはこちら
https://medpeer.co.jp/recruit/entry/
■開発環境はこちら
https://medpeer.co.jp/recruit/workplace/development.html