CTO 室 SRE kenzo0107 です。
以前執筆した ECS を利用した検証環境の自動構築について、運用開始から3年の時を経ました。
実運用とその上で頂いた要望を取り入れ変化してきましたので、その経緯を綴ります。
本稿、議論を重ね改善を進めて頂いたチームメンバーの知見を集めた元気玉ブログとなっております。
前提
社内では、以下の様に呼び分けしています。
- 本番相当の検証環境を STG 環境
- 本記事で説明する自動構築される仕組みを持つ環境を QA 環境*1
検証環境の自動構築の目的
開発した機能を開発担当者以外でも簡易的に確認できる様にし、以下を促進します。
- ディレクターと開発者の仕様齟齬を減らす
- 改善のサイクルを高速化する
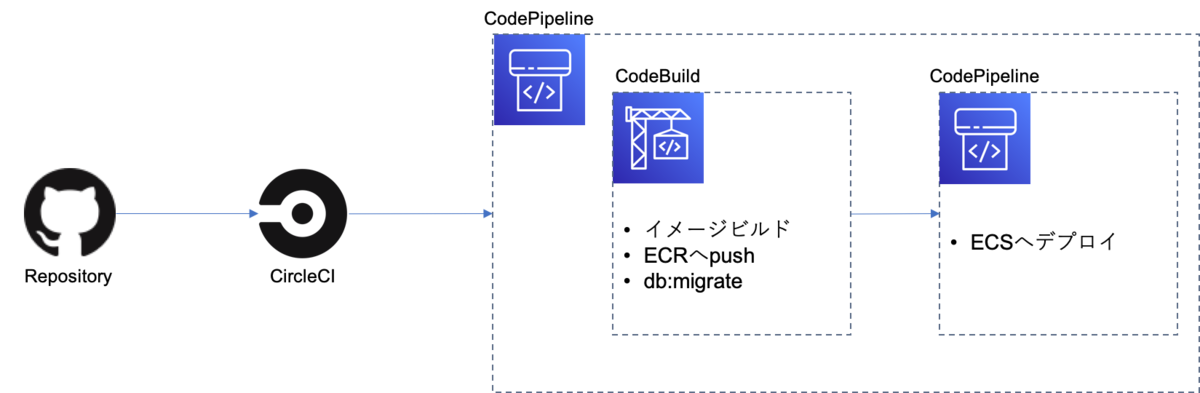
当時の検証環境の自動構築の仕組み
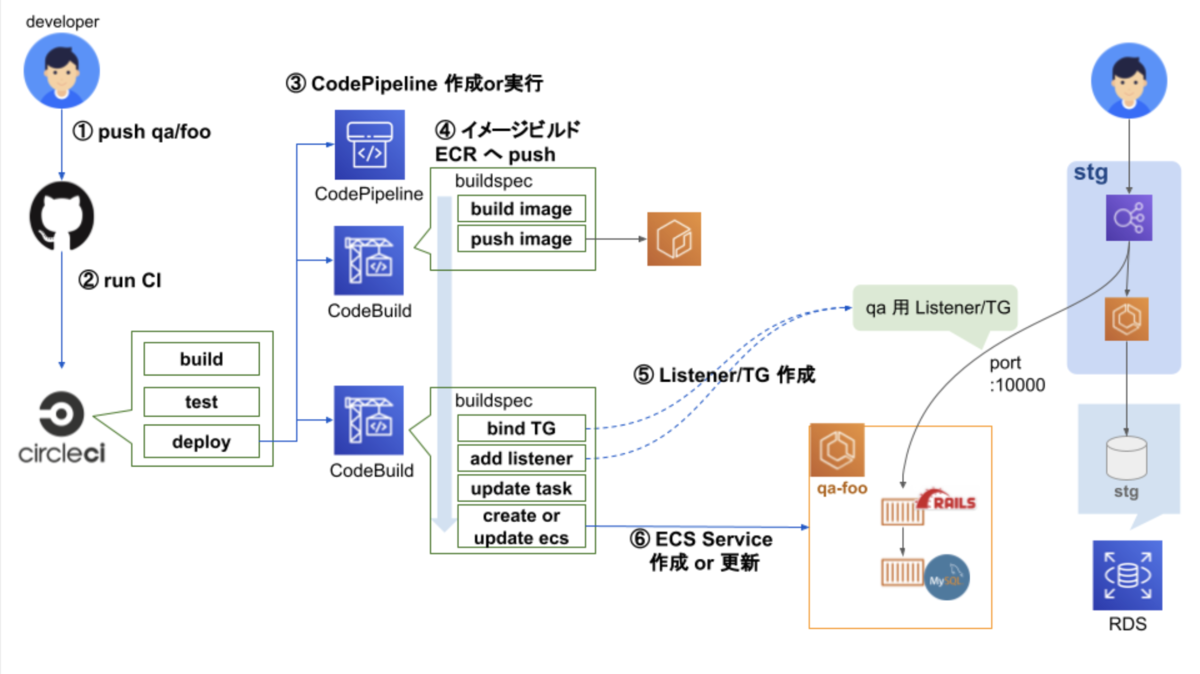
大まかな流れ
① ブランチ qa/foo を push
② CircleCI 実行
③ CodePipeline 作成 or 実行
④ Rails イメージビルドし ECR へ push
⑤ TargetGroup, Listner を 既存 STG 環境 LB に追加
⑥ ECS Service 作成 or 更新を実行
ブランチ qa/foo に push すると ECS Service を作成・更新する、
という仕組みです。*2
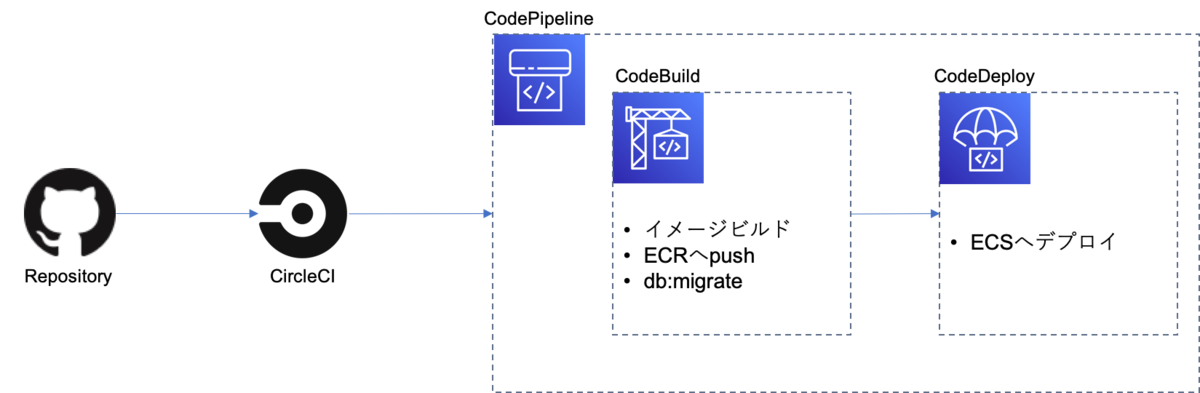
最新の仕組み
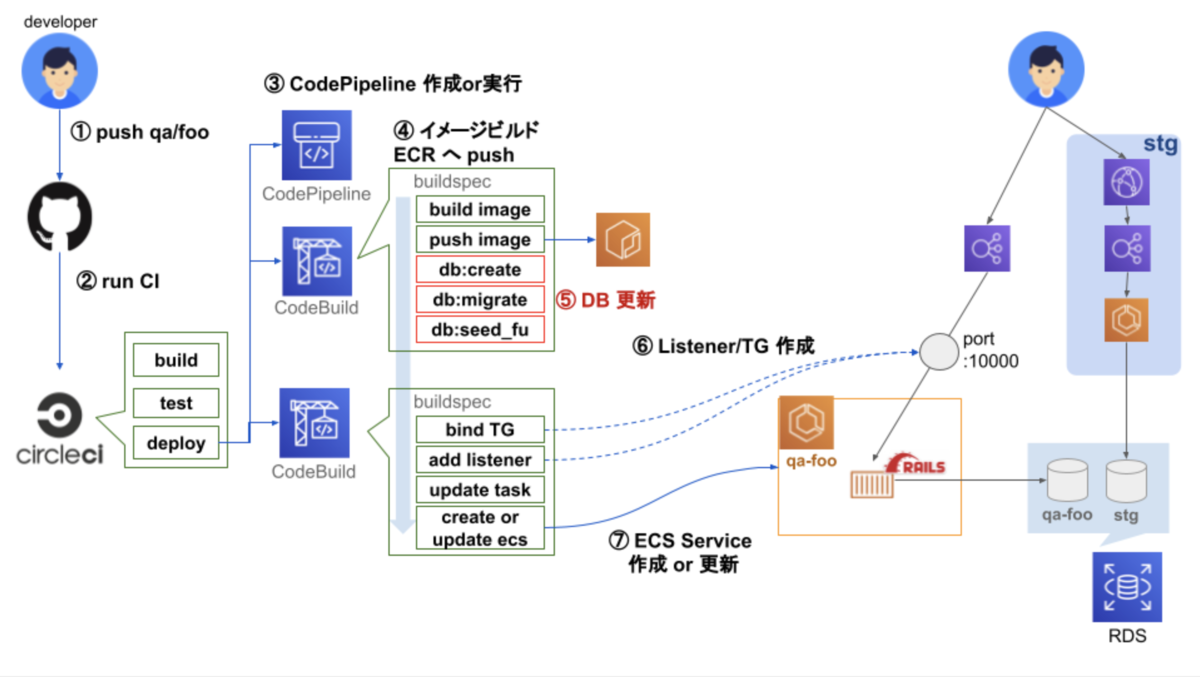
大まかな流れ
① ブランチ qa/foo を push
② CircleCI 実行
③ CodePipeline 作成 or 実行
④ Rails イメージビルドし ECR へ push
⑤ DB 更新
⑥ TargetGroup, Listner を QA 環境用 LB に追加
⑦ ECS Service 作成 or 更新を実行
当時と最新の検証環境の自動構築の仕組みの違い
- QA 環境用の LB を用意
- CodeBuild 内で DB 更新
- 既存 STG DB に QA 環境用 スキーマ作成
この様な仕組みへと変わった歴史を見ていきたいと思います。
構築当初の問題と解決の歴史
問題1: デプロイする度に DB データが初期化される
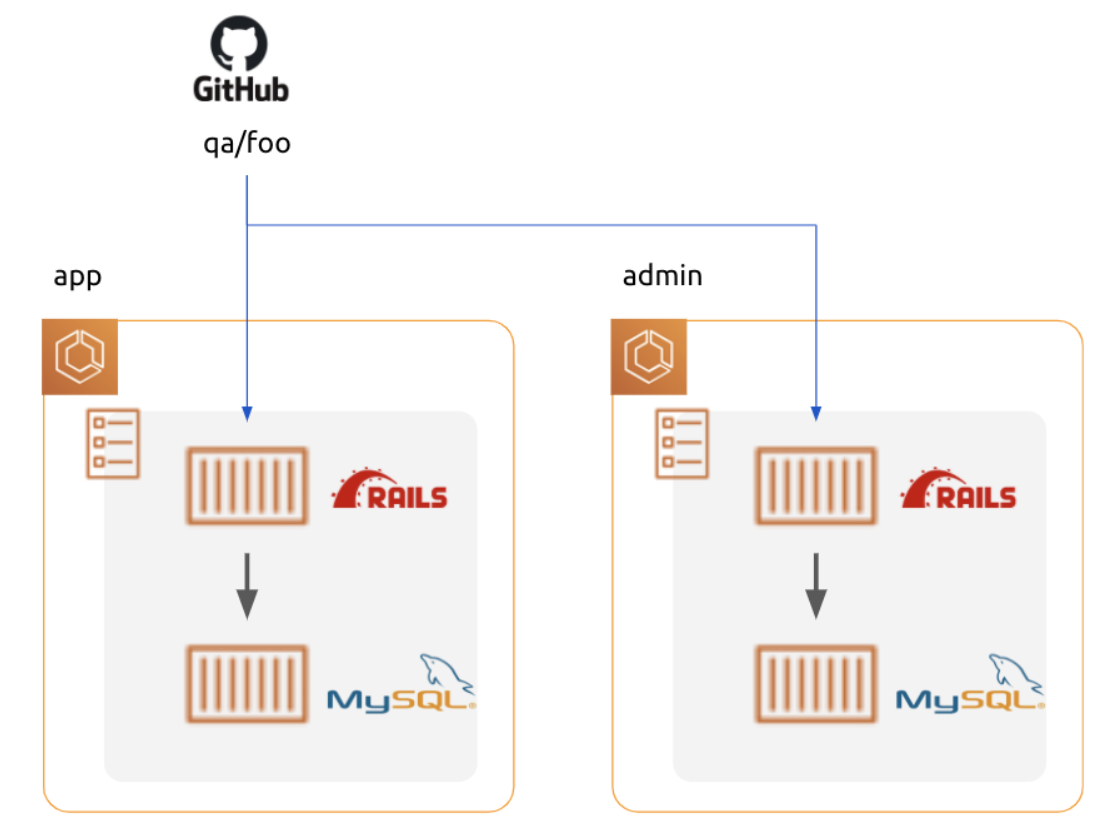
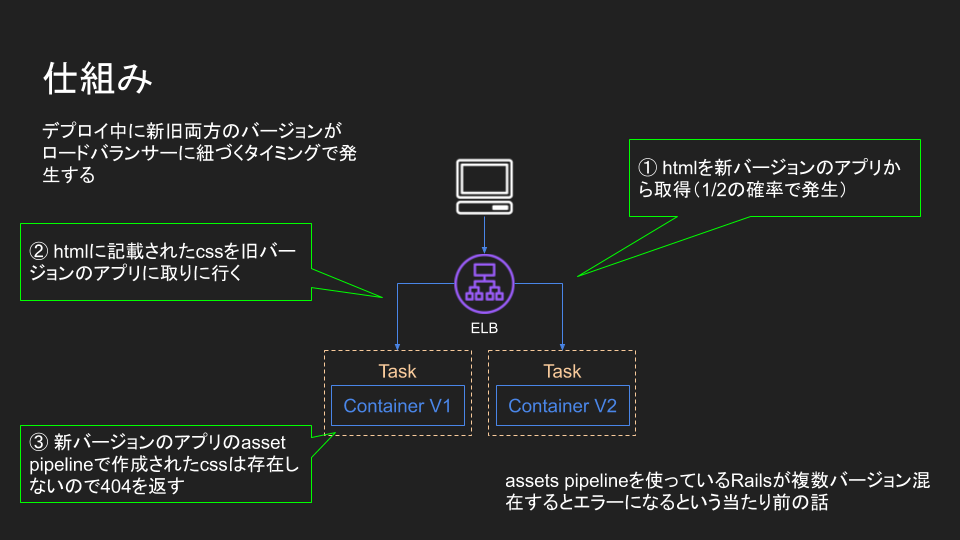
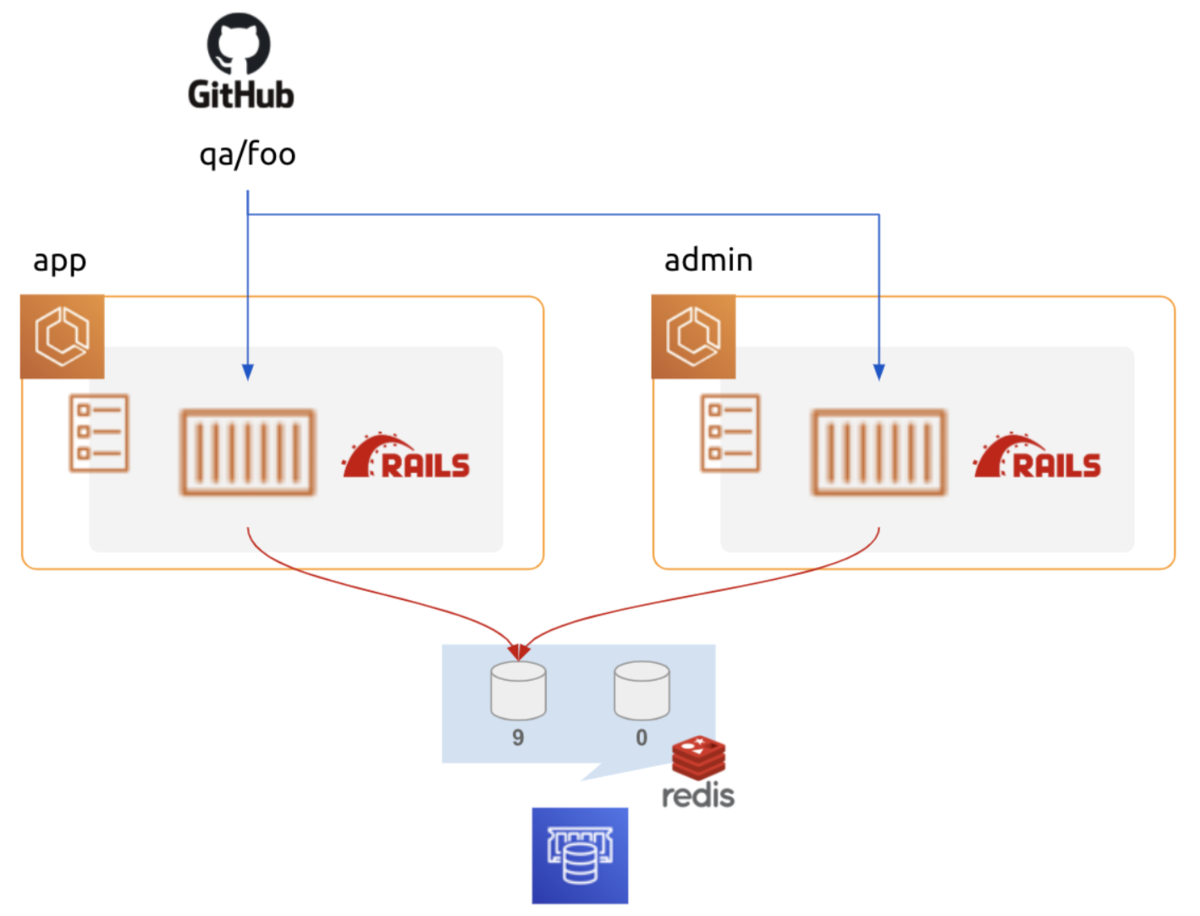
当初、 QA 環境は上図の構成を取っていました。
role (app, admin) 毎に別々にタスク内にDB コンテナを起動し、参照しています。
DB コンテナはデータを永続化していません。
デプロイ毎にデータが初期化されてしまいます 😢
もう一つ問題があります。
app と admin で共通の DB を見ていない為、app で更新したデータを admin で参照できません。
「検証環境」と言っておきながら、role 間 (app と admin 間) のデータの検証はできないんですね(笑)
と、妄想で闇落ち仕掛けましたが、次の方法で解決しました。
解決1: ブランチ毎に role 間で共通の DB スキーマを作る
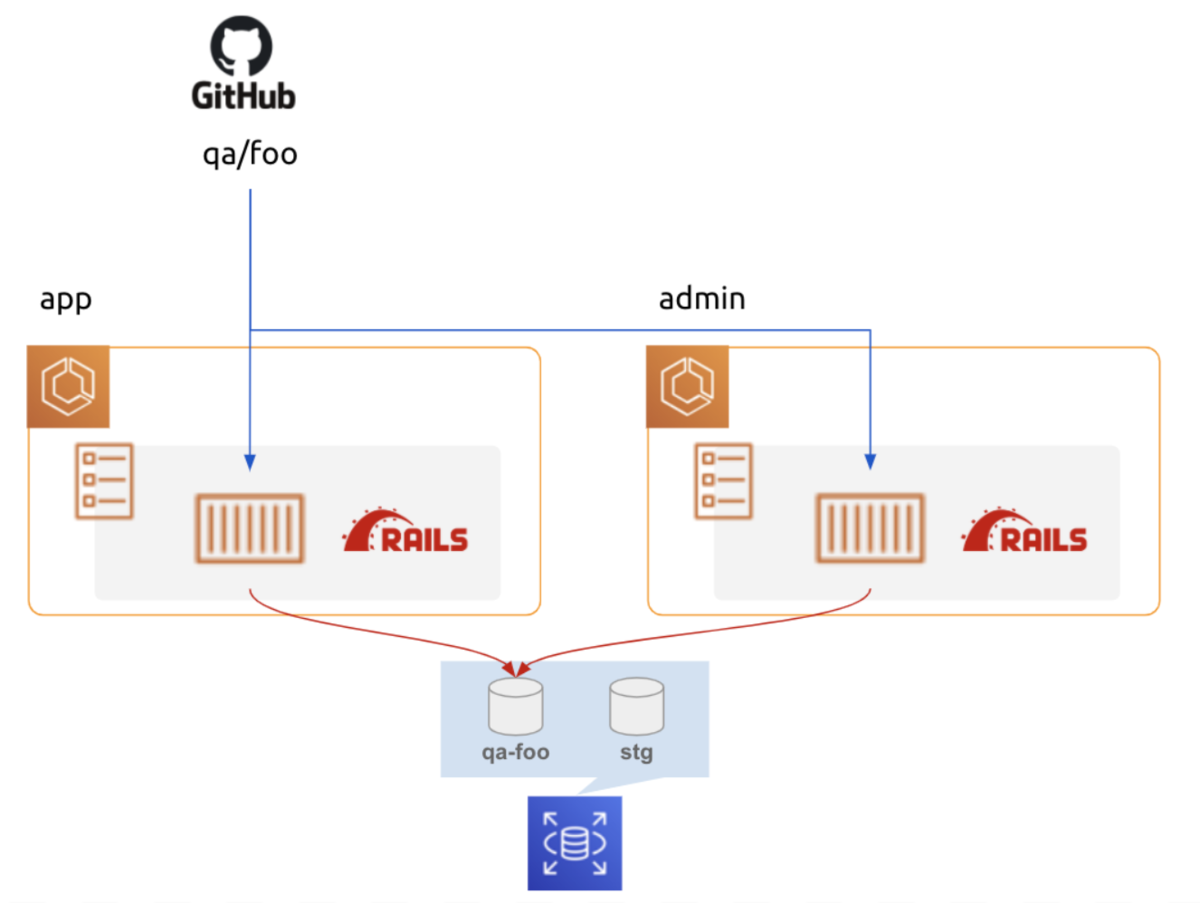
STG 環境 DB に ブランチ qa/foo に紐づくスキーマを作成し参照します。
これにより、ブランチ毎に DB を新規作成することなく、低コスト且つ、 既存 STG DB への影響も少なく目的が達成されました。*3
- config/database.yml
default: &default ... url: <%= ENV['DATABASE_URL'] %> staging: <<: *default - database: 'hoge_rails_staging' + database: <%= ENV['DB_NAME'] || 'hoge_rails_staging' %>
- タスク定義
{
"containerDefinitions": [
{
"name": "web",
"environment": [
{
"name": "DB_NAME",
"value": "qa-foo"
},
],
"secrets": [
{
"name": "DATABASE_URL",
"valueFrom": "xxxxxxx"
}
],
...
問題2: ECS Service に oneshot で db:migrate 等実行エラー発生後も処理が停止されない
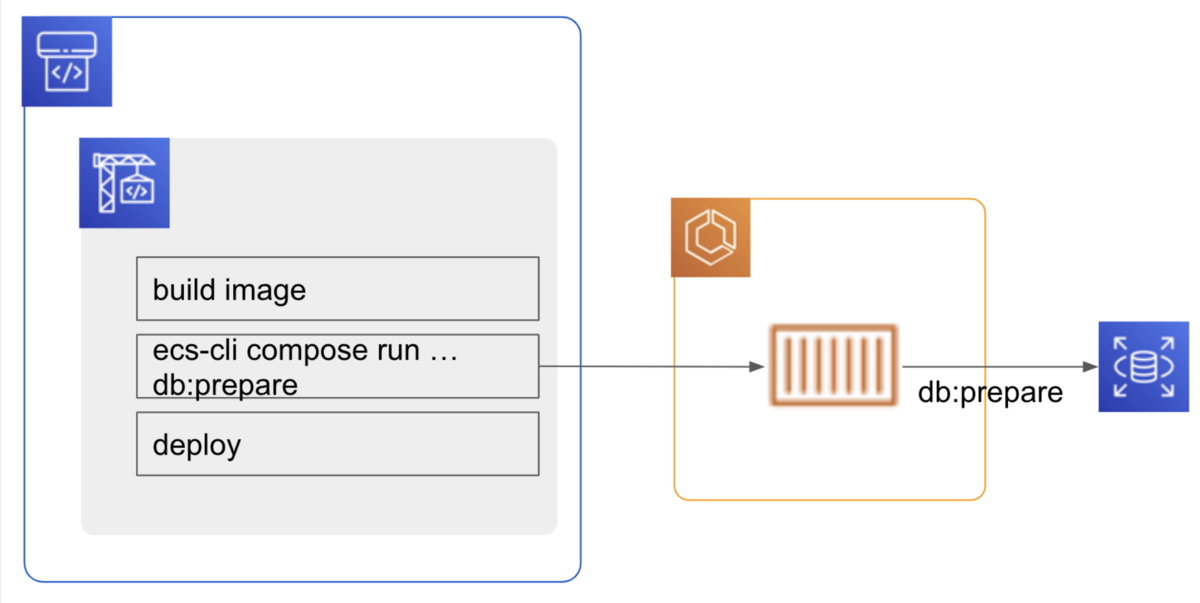
当初、AWS 公式の ECS 特化ツールである ecs-cli を採用していました。
ecs-cli compose run で ECS Service でタスクを起動し db:migrate, db:seed を oneshot で実行していました。
タスク起動時のリソース不足等で db:migrate が失敗しても処理が停止されない問題がありました。
実行結果のログこそ取れています。
ですが、ログを grep してエラー判定するのは、全エラーパターンを把握しておらず、取りこぼしがある可能性があります。*4
以下の方法で解決しました。
解決2: db:migrate 等 DB 操作は CodeBuild から VPC 接続し実行する
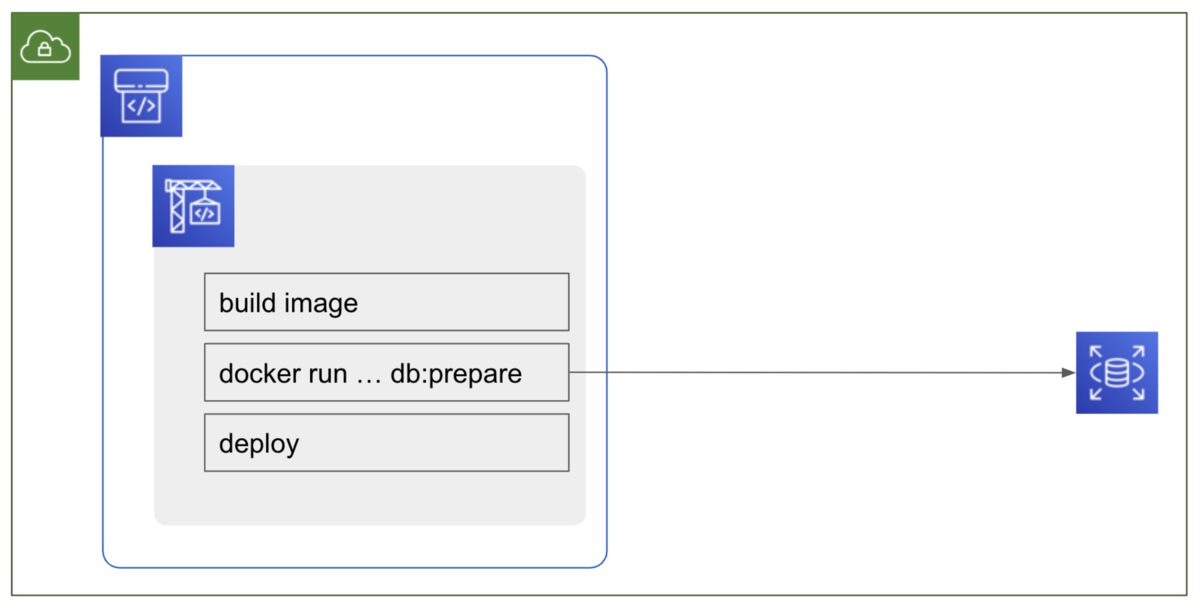
db:migrate 等 DB 操作は ECS Service 上でなく CodeBuild 上で実施する様にしました。
不要となった ecs-cli を削除し、コードも見通しがよくなりました。*5
- buildspec.yml
build:
commands:
- >-
docker run --rm
-e RAILS_ENV=${rails_env}
-e RAILS_MASTER_KEY=$RAILS_MASTER_KEY
-e DATABASE_URL=$DATABASE_URL/$DB_NAME
${repository_url}:$IMAGE_TAG bin/rails db:prepare db:seed
DB は Private Subnet 上にあるかと思いますが、
その場合、 CodeBuild から VPC 接続し起動する必要があります。
resource "aws_codebuild_project" "web" {
...
# NOTE: rails のイメージビルド後にこの CodeBuild から db:migrate を実行する
# RDSへ接続できるようにVPC内でCodeBuildを実行する
vpc_config {
vpc_id = aws_vpc.main.id
subnets = aws_subnet.codebuild.*.id
security_group_ids = [aws_security_group.codebuild.id]
}
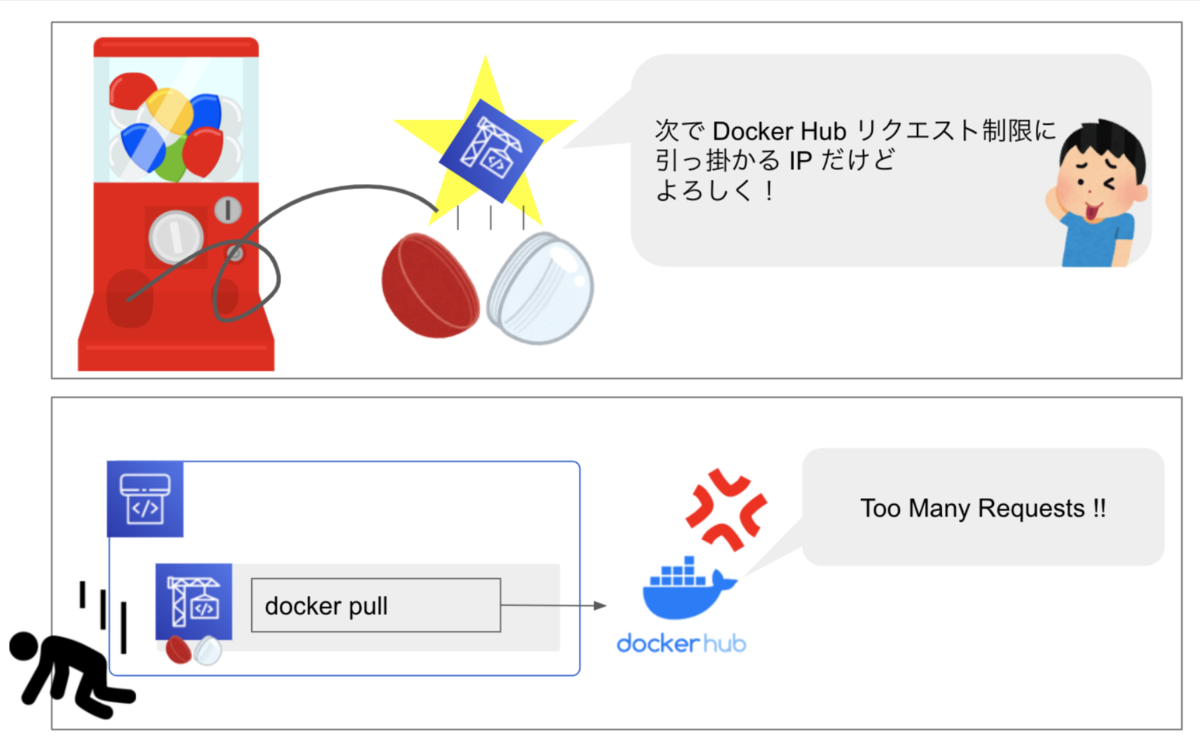
CodeBuild を VPC 接続し起動した副産物
CodeBuild で Docker Hub からイメージを pull しています。
通常 CodeBuild は任意の IP で起動します。
その為、既に Docker Hub へ多数のリクエストをした IP を引いてしまうことがあります。
所謂、「CodeBuild IP ガチャ問題」です。
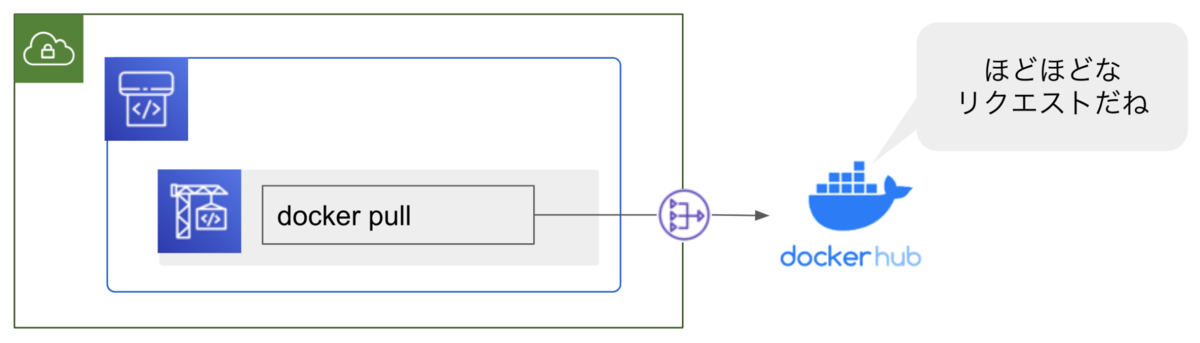
VPC 接続したことで Nat Gateway で出口 IP を固定し、使い回し IP を利用することがなくなる為、現状の利用頻度では、Docker Hub リクエスト制限を回避できました。*6
問題3: デプロイ毎に Redis データが初期化される
当初、DB 同様、Redis もタスク内にあり、role 毎に分離した構成になっていました。
主に Redis は Sidekiq のキュー管理で利用しています。
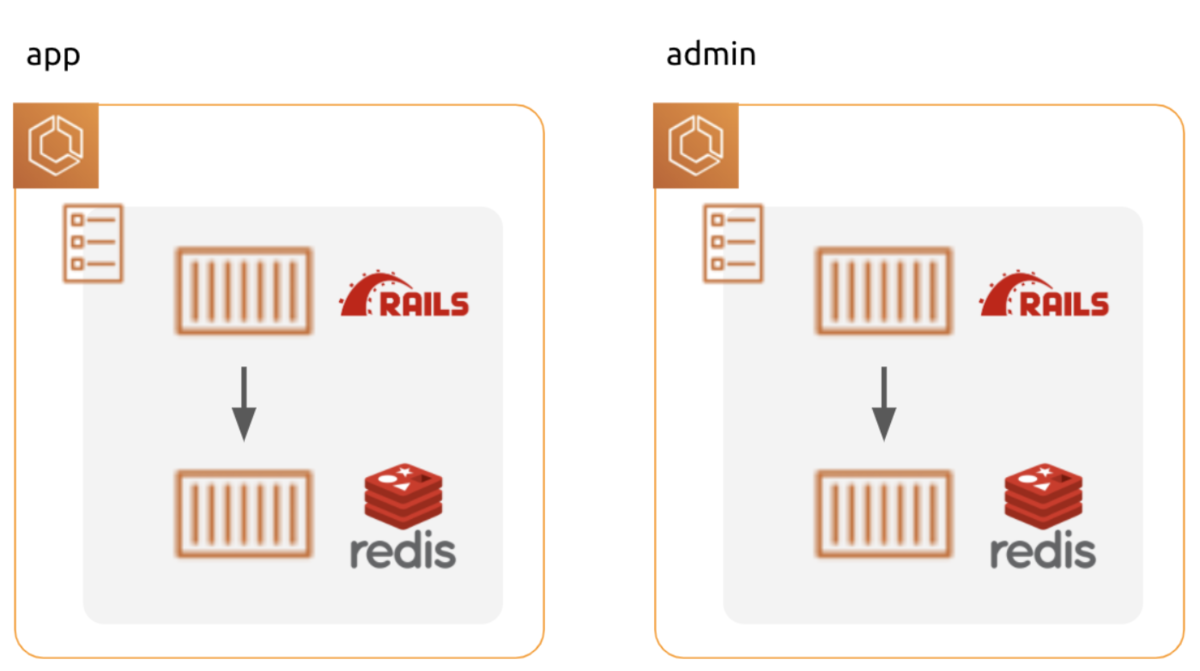
Redis も DB と同様、 QA 環境毎に role 間で共通のデータを参照できる様、対応が必要です。
解決3: Redis も role 間で同じデータを参照しよう!
解決3-1. Redis DB 番号で分ける
まず Redis の DB 番号で STG と QA 環境で分けます。
Rails に渡す Redis URL は以下の様にします。
- STG: rediss://stg-hoge.xxxxxx.apne1.cache.amazonaws.com:6379
- QA: rediss://stg-hoge.xxxxxx.apne1.cache.amazonaws.com:6379/9
redis(s) と s が 1 つ多いのはスペルミスでなく、伝送中 (In-Transit) の暗号化を有効化している為です。*7
QA 環境は DB 番号 9 を指定しています。*8
ただこれだけでは、 qa/foo, qa/bar の QA 環境は同じ 9 を利用し、干渉します。
解決3-2. gem redis-namespace で QA 環境毎の干渉を回避
gem 'redis-namespace' を採用し、同じ DB 番号 9 内で namespace を指定し QA 環境毎に分離し、データを干渉しない様にしました。
QA 環境の Rails.env = staging です。
Sidekiq 側で QA 環境が起動する staging に namespace の指定をします。
- config/application.yml
staging:
redis:
:url: <%= ENV['REDIS_URL'] %>
# NOTE: BRANCH = develop もしくは、 qa/xxx が設定される。
namespace: <%= ENV.fetch('BRANCH', nil)&.gsub('/', '_') %>
- config/sidekiq.rb
Sidekiq.configure_client do |config| config.redis = Settings.redis.to_h end
問題4: QA 環境のタスクが増え過ぎて DB が Too many connetions エラー
QA環境がカジュアルに利用される様になり、起動するタスクが増え、 DB で Too many connections エラーが多発する様になりました。
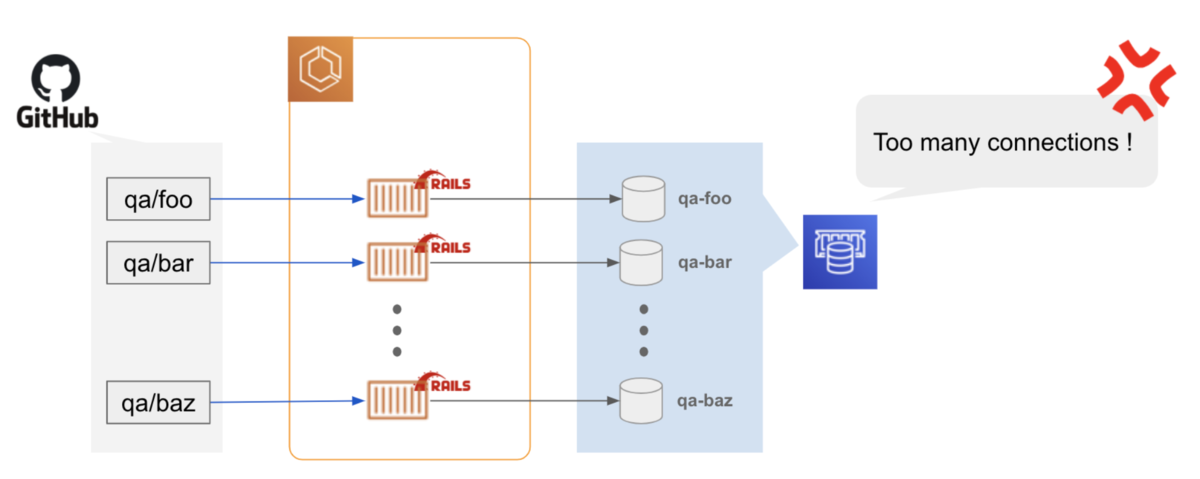
解決4: QA 環境のタスクのみ RAILS_MAX_THREADS を抑える
QA 環境のタスクのみ RAILS_MAX_THREADS を抑え、DB コネクション数を抑えることで暫定対応としました。
極力 DB スペックアップによるコスト増を避けたい意図です。
何かと相乗せ相乗せでコスト削減してますが、 弊社も希望と予算の合意が取れればスペックアップするんですよ 💸 *9
問題5: QA 環境にはどこまでリソースが必要か?
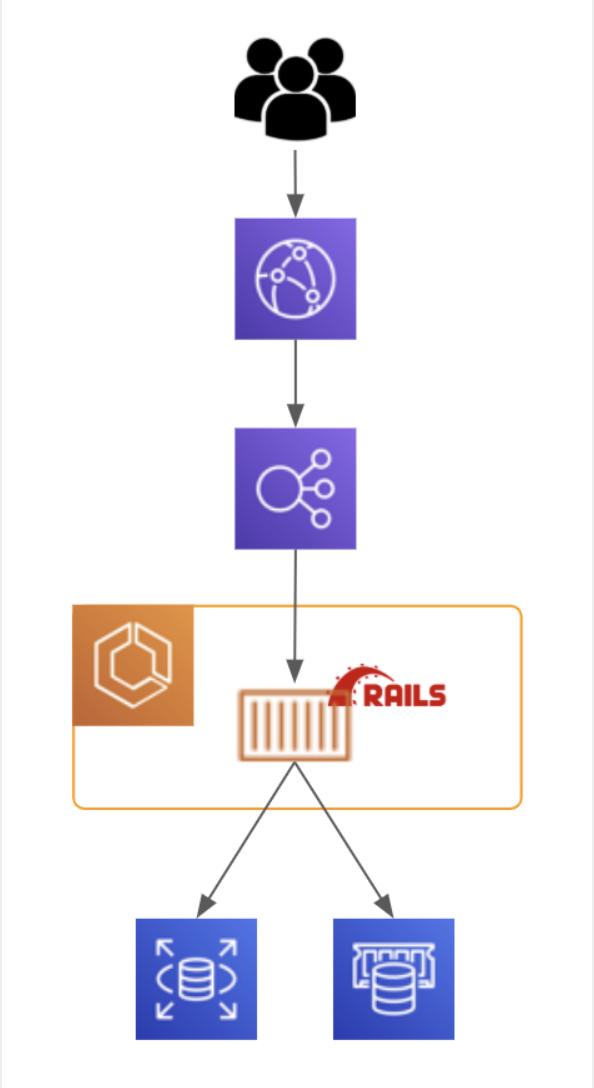
メドピアの最新のデファクトとなりつつあるアーキテクチャは上記図の通りです。
CloudFront を前段に配置しています。 レスポンスの高速化と AWS Shield の恩恵を受ける為です。
QA 環境はどこまで検証の為のリソースを用意する必要があるでしょうか?
RDS, ElastiCache は STG 環境に相載せしてきましたが、 CloudFront, ElasticsearchService, S3 等も用意すべきでしょうか?
解決5: 機能の検証に必要なリソースのみ用意する
CloudFront は ALB の様にポートによるルーティングができません。*10
その為、QA 環境で CloudFront を利用するにはブランチ qa/xxx 毎に構築する必要があります。*11
ですが、
CloudFront を毎回構築するのは時間が掛かります。
直ちに検証できる状態にならないデメリットがあります。
その為、
「CloudFront の機能を前提とした機能の検証は QA 環境ではしない」
という合意の元、QA 環境では CloudFront を採用しませんでした。
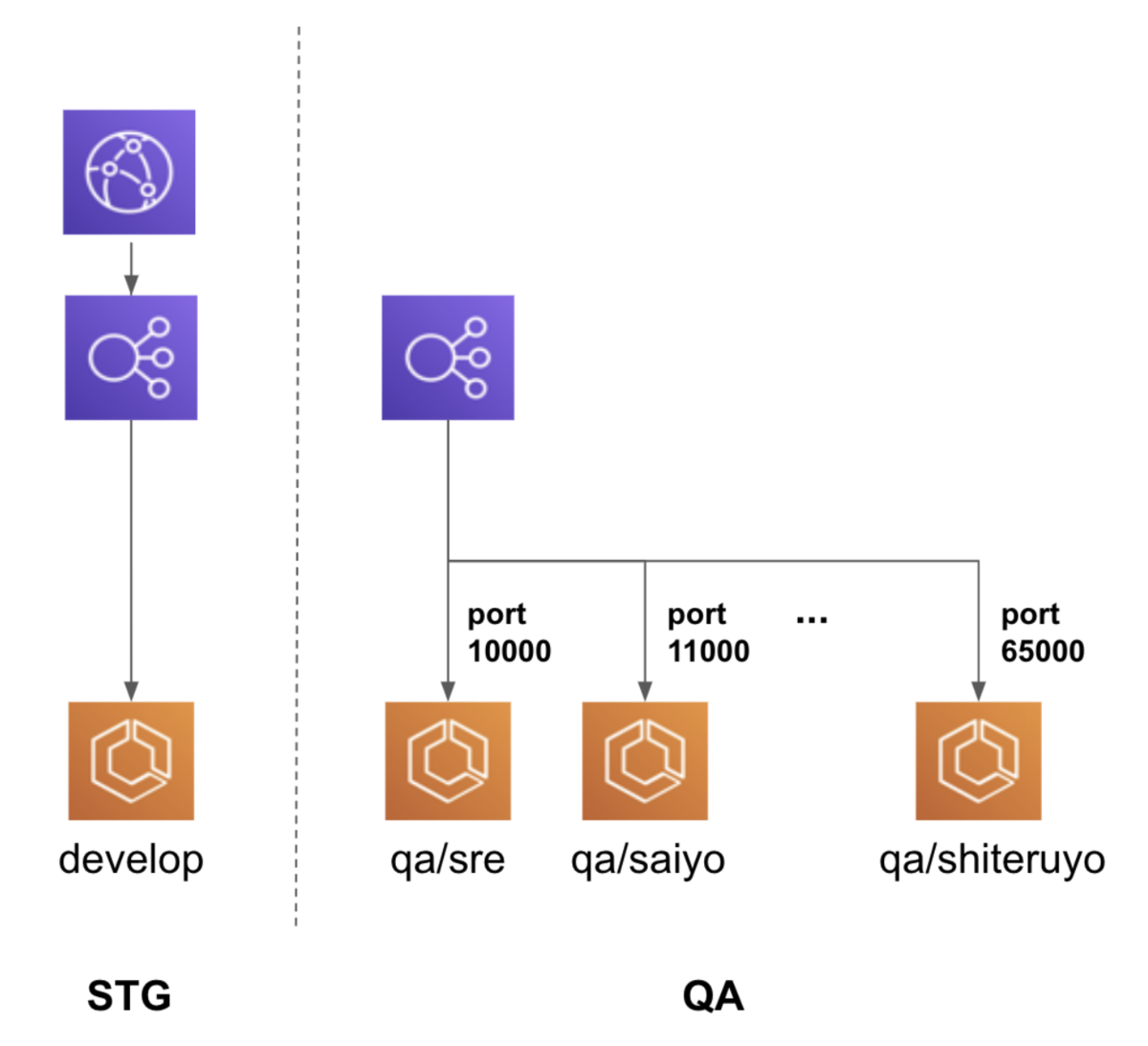
本番相当の検証は STG 環境で実施します。
まとめ
元々、必要になった経緯は、以下の依頼からでした。

依頼を言葉通りに受けていたら terraform で環境をコピーしたものを用意して終わっていたかもしれません。
ですが、依頼者の言葉を翻訳すると
「任意のブランチのコードが動く STG 環境相当の環境作って!」
でした。*12
この翻訳に掛けた時間がとても貴重だったと、運用を3年経過して思います。
そして、何より記事を書かねば!と至ったのは、このアーキテクチャが今まさに更なるアップデートを遂げている最中だからです。
その内容がブログに執筆されることを期待して筆を置こうと思います。
ご清聴ありがとうございました。
メドピアでは一緒に働く仲間を募集しています。 ご応募をお待ちしております!
■募集ポジションはこちら
https://medpeer.co.jp/recruit/entry/
■開発環境はこちら
https://medpeer.co.jp/recruit/workplace/development.html`
*1:Quality Assurance の手助けになれば、と当時発足した QA チームとかけて QA としました。「QA 環境って何ですか?」と新入社員に聞かれることも多く、誤解招く命名だったなと思う。ごめんなさい。名前大事。運用を経て用途として「気軽に試せる場所」という意味合いが強くなってきたので sandbox に改名することを検討中
*2:ブランチ qa/xxx 削除時に Webhook → Lambda 関数で作成した QA 環境のリソースを削除しています。
*3:ブランチ qa/xxx 削除時に Webhook → Lambda 関数で作成した DB スキーマ削除しています。
*4:capistrano でラップしていた影響もあるかもしれません。未検証です。すいません。
*5:ecs-cli は CodeBuild にプリインストールされていない為、インストールするコードを書く必要があります。
*6:あくまで暫定対応ではありますが、現状の利用頻度では効果覿面でした。
*7:Redis クライアントに hiredis を利用している場合、SSL サポートが安定してない為、注意が必要です。 https://github.com/redis/hiredis-rb/issues/58
*8:"Q"A 環境だから 9 がしっくりきたのもありますが、 0-8 は STG 用、 9-16 は QA 環境用に使えるかな、という今後の運用の予備をとっておきたい意図から 9 にしています。
*9:DB の max_connection を調整したりと極力スペックアップを回避しつつ、どうしてもというときは勿論インスタンスクラスをアップします。
*10:QA 環境のエンドポイントの分離にポートを採用したのは、非エンジニアでもアクセスを容易にしたい為です。ヘッダー情報や Cookie 等でルーティングする方法が非エンジニアには難易度が高く回避した経緯があります。
*11:Lambda@Edge でゴニョゴニョすればできそう?!とも思いましたが、アイディア浮かばず
*12:ブランチ駆動にしたのはこの依頼のまま受け取ってます。PR 単位でなくブランチ駆動にした方が構築される QA 環境の数が少なくて済み、コストが抑えられる為です💸